简介
针对字符串数据提供的解析方式。此规则将在6.3.1版本开始提供支持。
第二次修改版本:6.4.0
在使用前,请到AppStore上升级到最新版本。
不改变原内容的函数
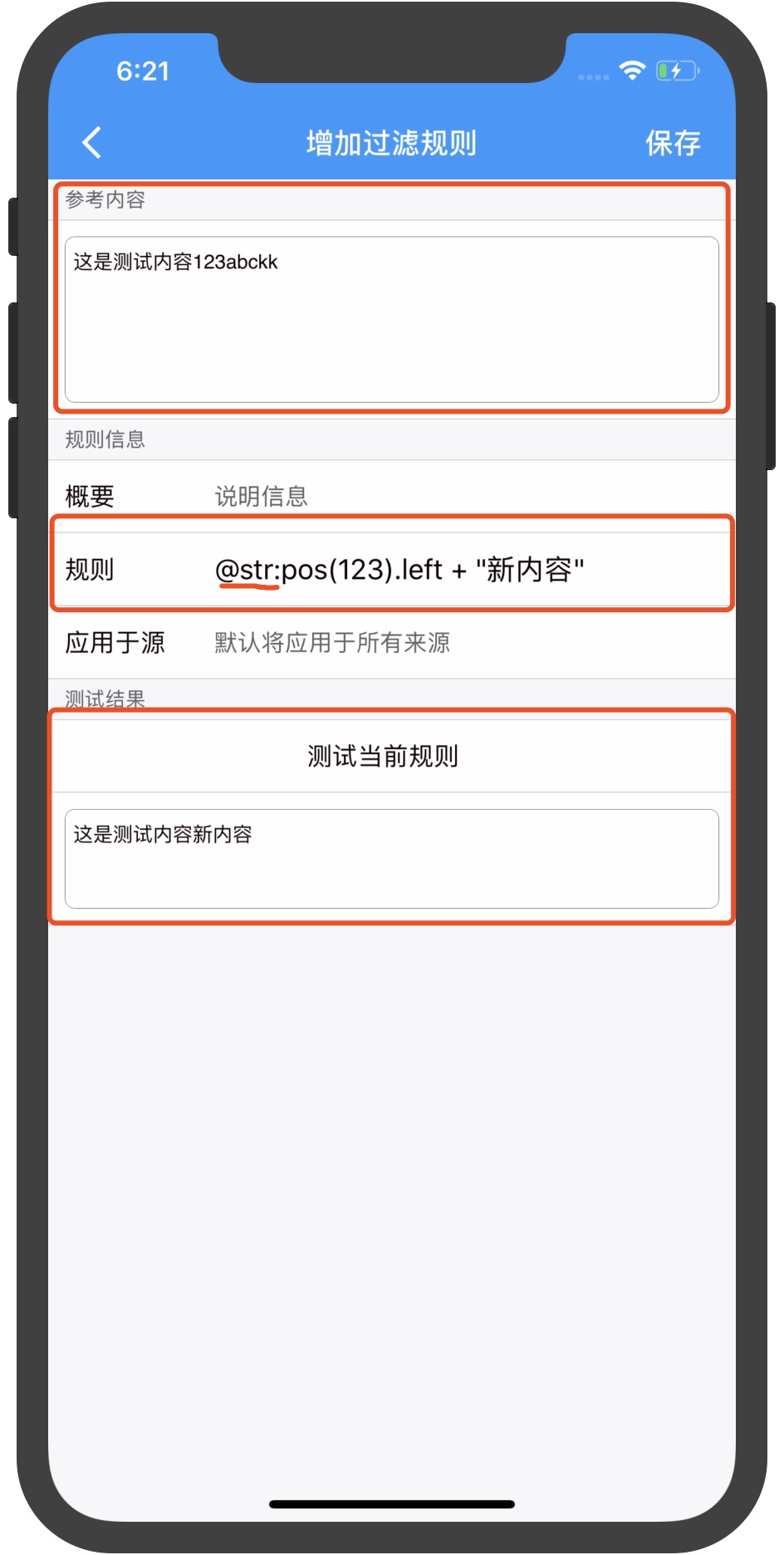
- pos(param)
查找指定字符串的位置, param表示要查找的字符, 不改变原内容。支持使用@mark[0]或@split[0]之类的来取值。 - rpos(param)
反向查找指定字符串的位置,param表示要查找的字符, 不改变原内容。支持使用@mark[0]或@split[0]之类的来取值。 - mark(param) 标志两个位置之间的字符串,param参数为可选:1包括前标志,2包括后标志,3包括前后标志,其它表示不包括前后标志, 不改变原内容。后续可使用@mark[0],@mark[1]之类的标志获取到的值
- split(param) 使用指定的子串将当前内容分隔为多个,不改变原内容,新的将替换旧的分割分组。后续可使用@split[0], @split[1]或来获取值。
将改变原内容
- left(param) 获取最后位置的左边字符串。param参数为可选:1包括标志,其它表示不包括标志。
- right(param) 获取最后位置的右边字符串。param参数为可选:1包括标志,其它表示不包括标志。
- trim 对字符串的前后空格进行删除
- mid(param) 获取两个位置之间的内容。param参数为可选:1包括前标志,2包括后标志,3包括前后标志,其它表示不包括前后标志。
- del(param) 删除两个位置之间的字符串。param参数为可选:1包括前标志,2包括后标志,3包括前后标志,其它表示不包括前后标志。
- sub(p0, p1) 获取给定两个位置之间的内容, 参数不提供表示0,p0 == p1时,取一个字符;p1 < p0 时,表示取到最后。
- replace(oldParam, newParam) 使用新字符串替换旧字符串; 若要过滤英文)与英文,符号的话,必须加转义符)与\,。支持使用@mark[0]或@split[0]之类的来取值
- + 将两段字符串连接起来
- " 用两个英文的"号括起来一段内容表示一个新的字符串,如 "新内容" + pos(123).left 此符号容易输错,请不要输入中文的引号:""""""""
例子:
原数据:**abcdef123456789这是测试内容**
脚本1:pos(a).pos(34).mid
结果1:bcdef12
脚本2:pos(a).pos(34).mark.replace(@mark[0],我是中国)
结果2:a我是中国3456789
脚本3:split(de).@split[1]
结果3:f123456789
脚本4:pos(bc).pos(567).mark.replace(@mark[0],新内容)
结果4:abc新内容56789
原数据:abcdef很长的有规则的广告内容123456789
脚本5:pos(很长的).pos(告内容).mark(3).replace(@mark[0])
结果5:abcdef123456789
原数据:这是测内容123abc3
脚本6:pos(3).left+ "xx3x"
结果6:这是测内容12xx3x
如何在爱阅书香中进行测试
在主界面上,打开菜单,进入内容过滤规则界面,再打开菜单创建新的过滤规则。
在规则输入框里输入:@str:,后面就是具体的规则了